
一、背景
最近某省运营商O域核心业务系统的数据库计划从Oracle迁移至GaussDB,数据库服务器也从SUN小型机转到华为TaishanARM服务器。本人有幸参与其中,主要负责Oracle到GaussDB的数据迁移环节。数据迁移前期使用Datasync工具进行导数测试,但由于导数效率无法满足生产系统的停机要求,而华为这个时候正好推出新的迁移工具—SDR,于是利用SDR进行了一轮新的迁移测试。
1、环境信息
1)硬件配置信息
目标库Taishan服务器硬件配置信息如下所示:

源库Sun小机硬件配置如下所示:

2)软件配置信息
Taishan服务器操作系统及数据库软件版本如下所示:

源库Sun小机操作系统及数据库软件版本如下所示:

由于本次文章的重点不在于环境的搭建,所以操作系统及GaussDB的安装过程就不细述。
2、SDR产品描述
GaussDB SDR(Swift Data Replicator)是一款基于日志的实时CDC软件,支持对多种关系型数据库交易数据的实时捕获、转换与加载,主要应用于数据迁移、数据复制、异地容灾、应急备份、双业务中心、实时数仓/数据湖、查询卸载等场景。主要特点有:实时、高效的数据同步、丰富的异构同步能力、无插件、非侵入、安全无干扰和全程可视化运维管理等。
二、SDR的环境准备
- 支持源端为Oracle 9i及以上版本(测试使用的SDR版本只支持到11R2)
- 支持目标端为GaussDB 100 V300R100
- 持可选schema、可选表进行全量数据同步
- 支持可配条件导出源库数据,将满足条件的数据导入目标库
- 支持多表并发同步,可配置并发个数
- 支持单表数据的并发导出,可配置并发个数,不支持单表的并发导入
- 支持自动同步表结构,自动进行数据类型映射,类型映射见下表
1)硬件要求
SDR目前只支持x86的64位操作系统,对硬件资源的要求主要取决于源端数据库的数据变化量。

表 2-1 资源要求
2)软件要求

注:本次迁移测试将SDR部署在一台独立的x86服务器上,通过数据库业务端口访问两边数据库,由于大部分迁移操作都是平台网页进行,因此还建议准备一台能直接访问这台x86服务7007/7008/7009端口的windows服务器。
1、SDR工具准备
1)创建安装用户和目录(x86服务器上操作)
为SDR软件创建一个新用户,并创建一个安装目录/home/sdr:
su-root groupaddsdr useradd-gsdr-d/home/sdr-s/bin/shsdr chown-Rsdr:sdr/home/sdr/
2)切换到安装用户下,上传安装包
su-sdr ls-l/home/sdr/ depend.tgz GaussDB_SDR_8.0.RC1_RHEL_x86_64.tar.gz licence.dat.tar.gz
3)解压所有压缩包
tar-xfdepend.tgz tar-xfGaussDB_SDR_8.0.RC1_RHEL_x86_64.tar.gz tar-xflicence.dat.tar.gz
2、SDR工具安装
1)设置SDR_HOME环境变量
su-sdr exportDIP_HOME=/opt/sdr
2)执行安装
cd/home/sdr ./GaussDB_SDR_8.0.RC1_INSTALL CreatingdirectorySDR.pack Verifyingarchiveintegrity...Allgood. Uncompressingswiftdatareplicator100% SwiftDataReplicatorinstallation! ©2019HuaweiTechnologiesCo.,Ltd. SwiftDataReplicatorsoftwarewillinstallintodirectory[/home/sdr] PleaseinputSwiftDataReplicatorwebserverIPaddress:[127.0.0.1] PleaseinputSwiftDataReplicatorwebserverport:[7008] PleaseinputSwiftDataReplicatormanagerserverIPaddress:[127.0.0.1] PleaseinputSwiftDataReplicatormanagerserverport:[7009] PleaseinputSwiftDataReplicatorqueuetransferserverport:[7007] PleaseinputSwiftDataReplicatoradminserverport:[7006] PleaseinputSwiftDataReplicatorkafkacomponentport:[7005] PleaseinputSwiftDataReplicatordatabaseIPaddress:[127.0.0.1] PleaseinputSwiftDataReplicatordatabaseport:[1888] PleasesetdefaultSwiftDataReplicatorShareMemorySize: [1]-1GB [2]-4GB [3]-8GB [4]-16GB [5]-inputothervalue(GB) pleasechoose1,2,3,4:[1]4 Inputvalueandchoicelistbelow,pleaseconfirm: httpIPaddress:127.0.0.1 httpport:7008 ManagerIPaddress:127.0.0.1 ManagerPort:7009 TransferPort:7007 AdminServerPort:7006 KafkacomponentPort:7005 SDRDatabaseIP:127.0.0.1 SDRDatabasePort:1888 Sharememorysize:16G KafkaServerPort:7005 Pressanykeytobegininstall.(Ctrl-ctointerrupt) Uncompressingbin.tgz... Uncompressingdbpkg.tgz... Uncompressingetc.tgz... Uncompressinglib.tgz... Uncompressingweb.tgz... Waitafewofminutes,installingdatabase... Checkingparameters... Checkinguser... Checkingoldinstall... Checkingkernelparameters... Checkingdir... Checkingintegralityofrunfile... Decompressingrunfile... Warning:DialectScriptsnotfound!Butstillproceedinstallation Settinguserenv... Checkingdatadirandconfigfile Initiatedbinstance... Creatingdatabase... Changingfilepermissionduetosecurityaudit... Installsuccessfully,formoredetailinformationsee/home/sdr/zengineinstall.log. Refreshingconfig... Creatingdbuser... Initializedata... alldone→顺利安装完成
3)配置depend
进入depend目录。
cd/home/sdr/depend/ shenable.sh Enablesuccess
4)加载 licence文件
cd/home/sdr cplicence.datetc/ lsetc/ dip_config.xmllicence.datodbcinst.iniversionxlog.ini
5)启动SDR组件
启动组件前需要先加载环境变量
su-sdr cd/home/sdr/ ../env (1)启动后台数据库 cd/home/sdr/db/app/bin pythonzctl.py-tstart (2)启动其他组件 cd/home/sdr/ start_all (3)启动web服务 cd/home/sdr start_web
至此,SDR所有安装准备工作完成。
三、SDR配置
SDR管理界面需要通过浏览器进入,浏览器可选择chrome或IE 9.0以上。网址为x86服务器的IP,端口为安装时指定的端口,必须是HTTPS,如https://IP:port。初始帐号密码admin/admin。

图-1-登录 SDR 控制台
登录后,需要先新建一个项目。
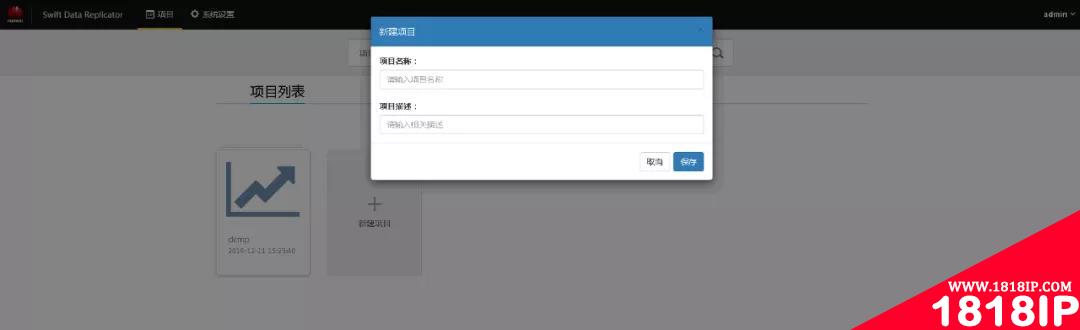
图-2-创建项目
输入项目名称,并保存。
点击进入项目后,会进入配置管理主界面。点击左上角的“新建”按钮,创建任务组。
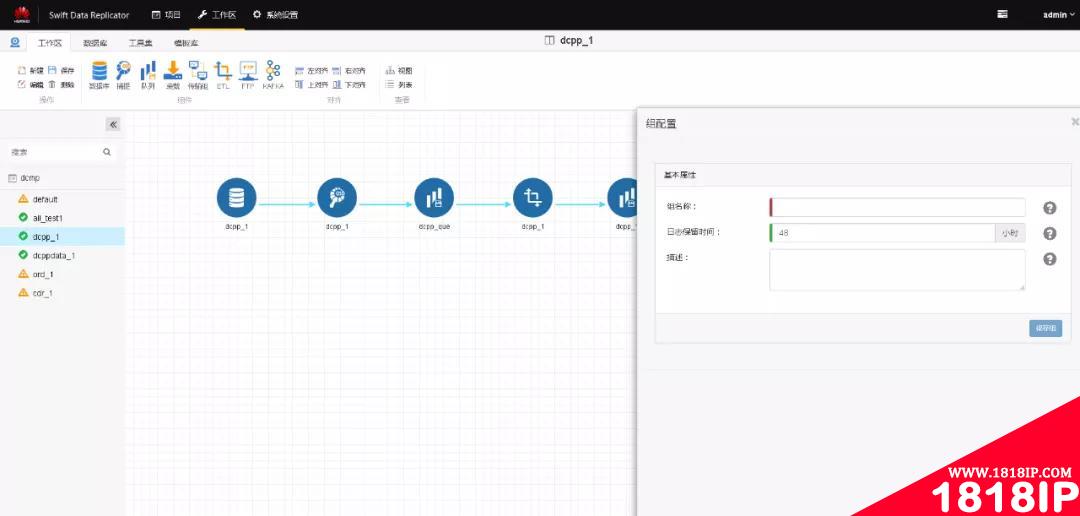
图 -3-新建任务组
输入组名,和该组下进程的运行日志保留时间,点击“保存组”。
本次迁移测试是从Oracle到GaussDB,属于异构数据库迁移,可以直接使用模板库中的异构链路进行配置,直接点击“异构链路”即可,如下图所示:

图 -4-异构链路配置
生成链路后,双击链路中的源库组件,在弹出的对话框中进行源库配置。(第一次配置后,可以选择作为模板保存,以便后续使用)。
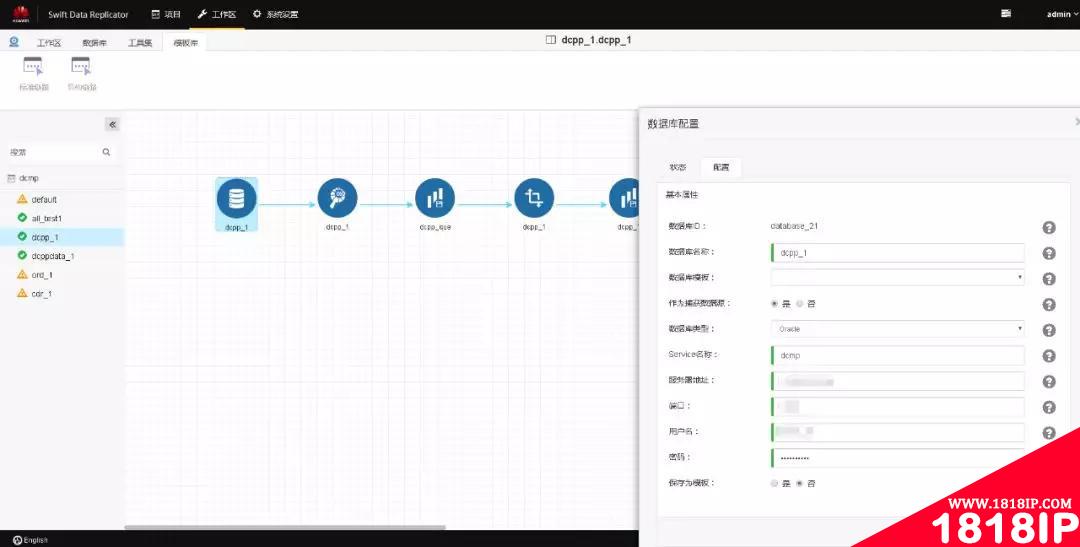
图 -5-源库数据库配置
注:源数据库类型为Oracle时需要对导出的对象添加附加日志,添加附加日志的SQL可以在“必要环境配置”中一键生成,并拿到源库中执行。
配置完源库信息后,接下来要配置捕获进程,捕获进程主要是用于从源库中抽数,可配置需要迁移的schema和对象类型,以及抽数时间间隔,分配内存等参数,配置如下:
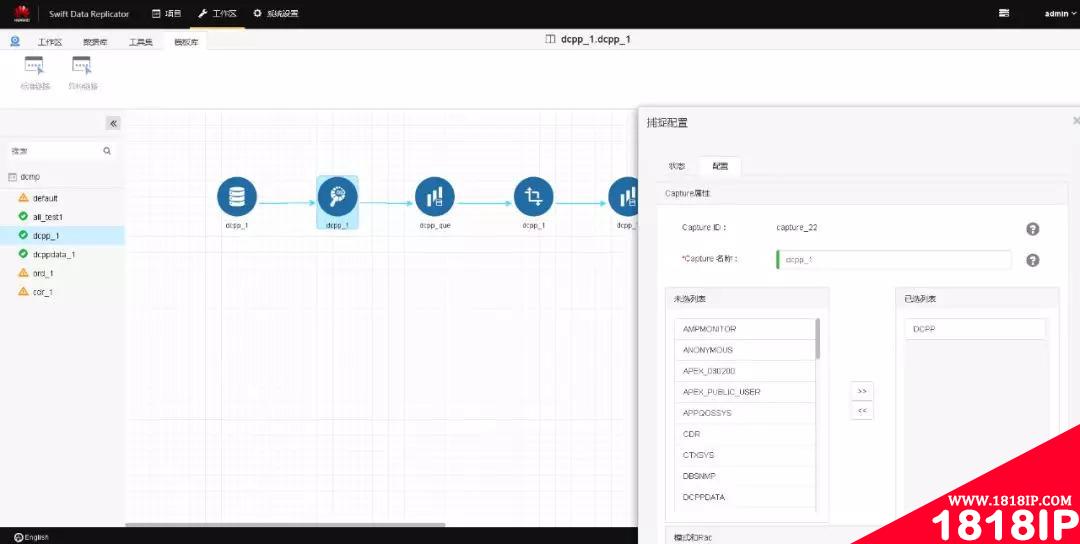
图-6-捕获配置
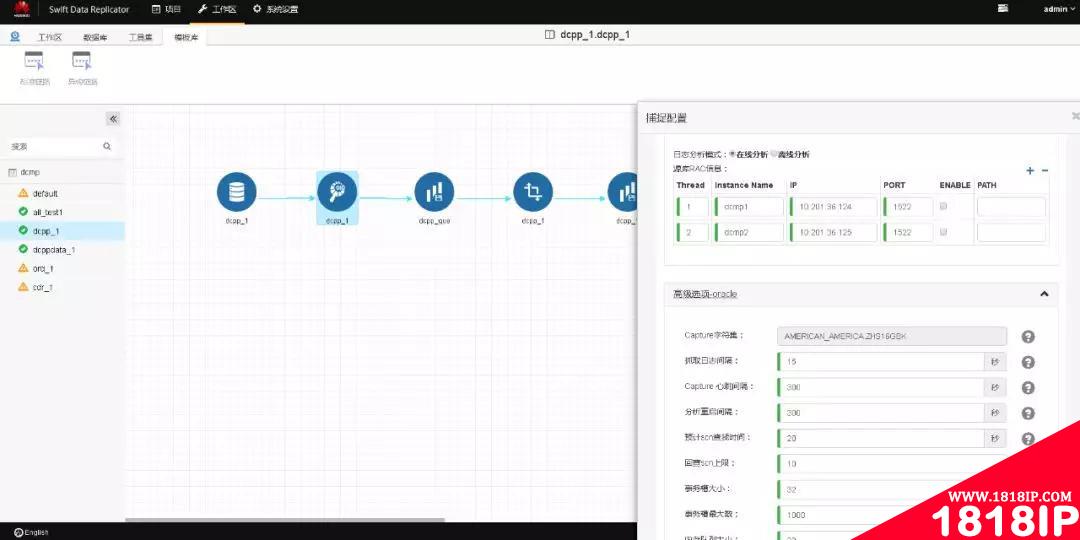
图-7-配置捕获进程的高级选项
注:源库为Oracle RAC时,需要把所有节点的信息都输入进去,并且选择“ENABLE”
配置好捕获进程之后,接下来需要配置队列信息。整个链路需要配置两个队列,一个是导出队列,一个是导入队列,可以先按顺序配置导出队列。具体配置如下:

图 -8-配置导出队列
队列配置完成后,需要配置ETL转换环节。在配置好源库信息后,ETL的大部分内容都会自动填充,直接使用默认配置就完事了。具体配置如下:

图 -9- 配置ETL
接着是配置导入队列,这里不多叙述。配置如下:
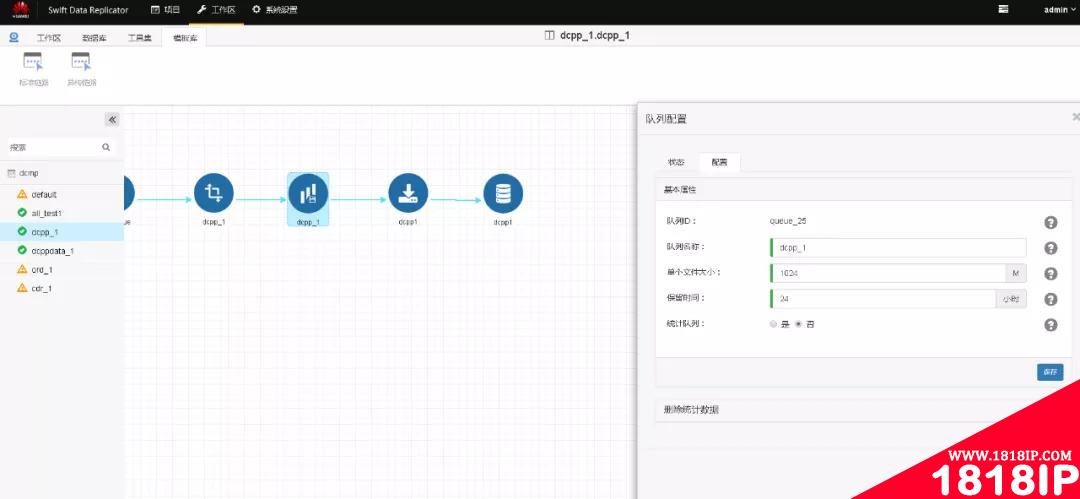
图 -10- 配置导入队列
按链路顺序,接下来是配置转载进程,但在配置之前,会提示需要先配置好目标库信息,所以只能先跳到最后的目标库信息配置,完成后再返回来配置转载进程信息。所以下面是配置目标GaussDB库的信息(同样,第一次配置时可以选择保存为GaussDB库的模板,方便后续使用。)
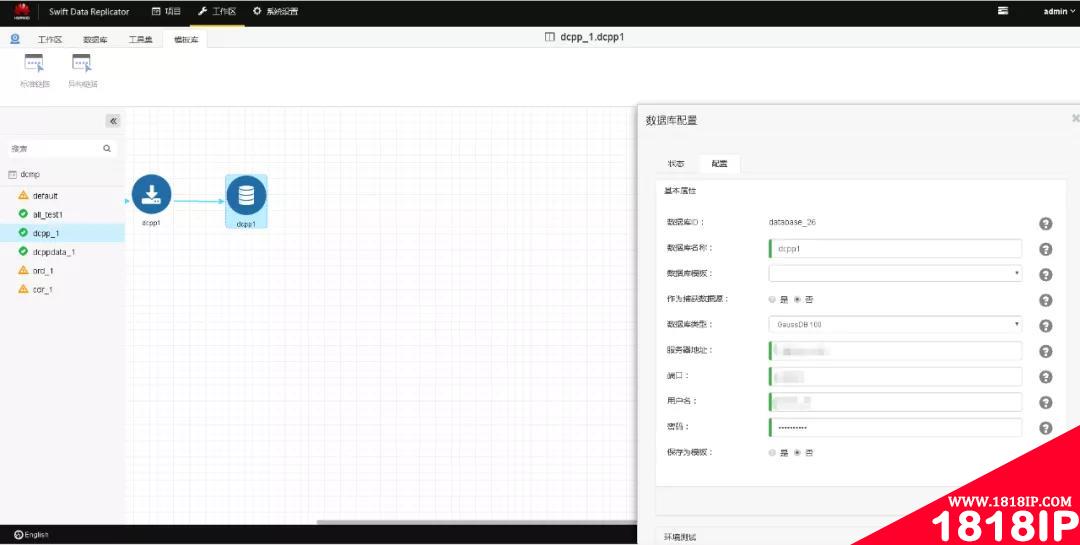
图 -11- 配置目标库信息
接下来终于可以愉快地配置转载进程信息了。转载进程可配置的内容比较多,主要分为:包含条件,排除条件和高级选项。
包含条件中可配置要导入的schema和对象类型,以及是否在目标库替换schema_name。(本次测试进行了schema_name的转换,测试结果顺利。)

图 -12- 配置装载包含条件
接下来是配置排除条件,本次测试没有添加排除条件,有需要的同学可添加测试。
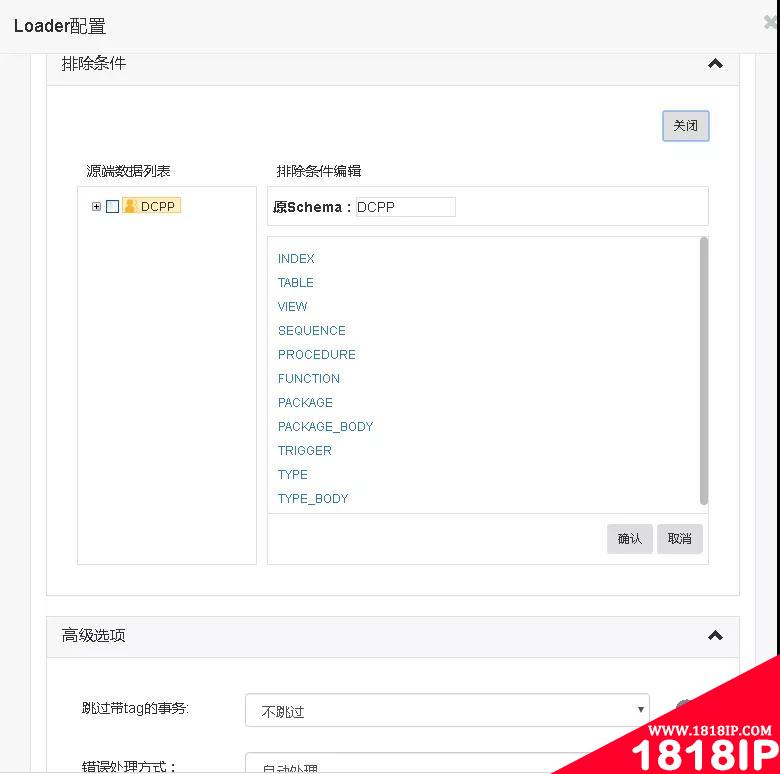
图 -13- 配置装载排除条件
下面是配置高级选项,下面截图是所有默认设置,可按需进行调整。
图 -14- 配置装载高级选项
确认保存后,迁移所需的各项组件配置完成。
四、SDR全量迁移
SDR工具自带数据初始化的功能,点击工具栏的“工具集 >存量数据同步”,弹出配置界面。可配置导出任务的并发数以及单表的并发数,需注意控制并发数大小,极端情况可能会出现导出进程总数等于任务并发数 * 表内并发数。另外,“将数据导出为字符串”的选项必须勾选,不然速度虽然会极大加快,但是导出导入失败率也会大大提高。

图 -15- 配置全量数据同步-导出条件配置
(注:开启初始化之前,需要在目标环境手动创建用户/权限/表空间等,创建命令跟Oracle基本一致。)
导出条件配置完并保存后,接下来配置导入条件配置。由于目标库没有业务压力,并发数可选择大些,也可根据需求选择是否“重建目标表”,“清空目标表”和“重建索引”等选项。

图-16- 配置全量数据同步-导入条件配置
配置完成兵保存后,点击“开始全同步”后即开始存量数据同步。

图 -17-查看全量同步实时信息
等待导出导入完成后即存量数据的迁移工作。迁移过程存在的报错信息可以在“导出错误信息”和“导入错误信息”中直接查阅。如果报错信息缺失或不足,可以进入到x86服务器中安装目录的log目录查看更详细信息。
五、SDR增量迁移(正式迁移使用的步骤)
划重点!!前面的全量迁移和下面要说的增量迁移是两回事,如果按照前面步骤做完全量数据迁移,要做增量迁移也需要把目标库的数据全删掉重新再来!
在使用增备前,需要先从源库中获取最新的scn号。在源端Oracle库获取最新的SCN号:
selectcurrent_scnfromv$database; CURRENT_SCN ------------------ 16493654040783
1、开启捕捉进程
需要提前按文“SDR全量迁移”配置异构链路,这里不复述。配置完成后单独开启捕捉进程。在工作区选择捕获进程后,点击“启动”即可开启。

图-18- 开启捕捉进程
2、启动存量备份
这次存量备份需要把拿到的最新scn号输入进去,以便把这个scn号的所有数据都同步到目标库。

图-19- 配置存量数据同步
3、启动增备
等待存量备份完成后,单独开启转换和装载进程。以指定SCN方式启动转换进程,输入的scn就是在一开始获取到的最新SCN号。

图-20- 指定scn启动转换进程
ETL启动完成后如图:

图-21- 开启转换进程后
以指定SCN方式启动装载进程,输入的scn就是在一开始获取到的最新SCN号。

图-22- 指定scn启动装载进程
转载进程启动完成后,状态如图:

图-23- 开启装载进程后
都启动完成后,在工作区选择“列表”方式查看各进程状态,都为running则正常。

图-24- 列表方式查看状态
至此,增备启动完成。
增备发起后,源库对操作表的DML和DDL都会准实时同步到目标端,直到手动终止或报错为止。(部分DDL不支持,例如:add database,add datafile,role相关操作等等)
4、迁移过程问题
1)选择自动创建表的时候,分区表的分区信息(interval等)无法自动同步,导致导入GaussDB后分区表变回普通表
解决思路:在开始导数前,手动在目标环境创建所有分区表,在存量数据导入时不选择“重建表”选项
2)导出时,一个表上同时有long和clob类型的字段会报错
报错信息:table[dcpp.aqua_explain_1483468080]include LOB and LONG column,unsupport
解决思路:在开始导数前,手动在目标环境创建所有报错表,在存量数据导入时不选择“重建表”选项
3)启动存量数据同步时,即使是同样的配置选项,点击“开始全同步“后,经常出现同步进程无法正常启动的问题
具体现象是:
- 耗时:00H00M00S ,不开始计时
- 源库Oracle中,发起一个查询全量表信息的SQL后,没有继续执行具体表的导出SQL,而是直接终结会话
- 导出/导入报错信息中,没有任何信息
解决思路:多尝试几次,或者降低并发量。
六、小结
使用过程感觉SDR比较类似Oracle的OGG工具。工作流程可简化为:指定scn导入此scn前所有数据进行初始化,初始化完成后根据此scn开始自动增量同步,直至手动结束同步。整个迁移过程只需要前期配置好同步进程,后期人工介入的时间就非常少(定期检查同步进程状态和日志状态还是必须的),而且因为数据一直在准实时同步,因此生产系统上的迁移时间就可以压缩的非常短,可以预留更多的时间做数据校验和其他操作。
